脱初心者!周りに差をつける生成AI用語23選【中級編】


2025年に入っても熾烈な競争を繰り広げている生成AI業界。職場や街なかでも普及してきており、「活用している人・企業」と「活用していない人・企業」の差が広くなりつつあります。
生成AIについて初心者を脱したい
周りに差をつけたい!
周りのレベルが高い(汗)中級の用語を教えて!
この記事を読むことで、上記のようなニーズが解決します。
会話、ニュース、雑誌、広告……多くの場所で生成AIが話題にあがります。一日のうち、「生成AIを触らないことがない」という方も多いでしょう。
こんにちは、シントビ管理人のなかむーです。
私も毎日必ず生成AIを触っていますが、もっと良い使い方がないか、自分に知らない技術や概念がないか、と探し続けています。
今回も文系目線でわかりやすく解説していきます。
この記事を読むことで以下のことがわかります。
- 生成AIの利用や活用に関する中級レベルの用語
- 生成AIを支える中級レベルの技術
- 生成AIの課題や問題に関する中級レベルの用語
まずは初級編から学びたいという方は以下の記事も参考にしてください。ChatGPTの用語として解説しましたが、生成AI全般に通じます。

それでは早速用語を解説していきます。
生成AIの利用に関する用語|中級編

まずは肩慣らしです。
生成AIを利用する際、さまざまな専門用語が使われています。プロンプト、ハルシネーション、トークン、これらは初級編で紹介しました。中級レベルとしては以下の用語を知っておくと良いでしょう。
- パラメータ数(Model Parameters)
- マルチモーダル(Multimodal)
- メモリ(Memory)
- コンテキストウィンドウ(Context Window)
パラメータ数(Model Parameters)
パラメータ数はAIモデルの「脳」の大きさを表す数値です。新たなモデルが登場する際には、よく「このモデルのパラメータ数は◯◯億個」というように紹介されるので、聞いたことがある方も多いでしょう。
具体的には、モデル内部の調整可能な数値の総数で、数字が大きいほど複雑な情報を記憶・処理できます。例えばGPT-4は約1.7兆個のパラメータを持つと言われています。
このパラメータは人間の脳の神経結合のようなもので、多いほど複雑な知識や言語パターンを学習可能です。一般的に、パラメータ数が増えると、AIの応答の質や知識量が向上しますが、処理に必要な計算リソースやコストも増加します。
最近の生成AIの進化は、このパラメータ数の増加と効率的な設計によって支えられています。

マルチモーダル(Multimodal)
マルチモーダルとは、AIが複数の情報形式(「モード」)を同時に理解・処理できる能力のことです。当初の生成AIはテキストのみを扱うことが多かったのに対し、マルチモーダルAIは文章、画像、音声、動画などを組み合わせて理解できます。
2025年現在のChatGPTはマルチモーダルAIです。例えばGPT4oは画像を読み込ませて内容を説明させることや、音声で情報を入力するなどが可能です。
このようにさまざまな情報形式を理解・処理できる技術が発達することにより、より自然で多様なコミュニケーションが実現し、実世界の複雑な情報を総合的に理解できるAIが誕生しています。
ドラえもんのようなAIロボットが誕生する日も遠くないかもしれませんね!
メモリ(短期記憶・長期記憶)
メモリという言葉自体は、パソコンなどでよく使われる言葉です。生成AIにおいては、メモリは会話の履歴や重要情報を保持する機能を指します。短期記憶はトークン制限内での現在の会話内容で、長期記憶は会話を超えて保存される情報です。
例えば「私の名前は太郎です」と伝えると、AIはその後の会話でも名前を覚えていられます。従来のAIは会話が終わると全てリセットされましたが、最近では複数のセッションをまたいで情報を保持できる生成AIも登場しています。
これにより、前回の続きから会話を再開したり、ユーザーの好みや背景知識を活用した対応が可能になり、よりパーソナライズされた体験を提供できるようになります。
コンテキストウィンドウ(Context Window)
コンテキストウィンドウは、AIが一度に「覚えていられる」情報量の範囲を指します。例えば、ChatGPTのProプランでは約128,000トークン(英語で約10万語、小説1冊分程度)のコンテキストウィンドウが提供され、この範囲内のすべての情報を参照しながら会話が可能です。

これは人間の「ワーキングメモリ」に似た概念で、会話の履歴や提示された資料を覚えておける容量にあたります。コンテキストウィンドウが大きいほど、長い会話や複雑なドキュメントを理解できますが、処理に必要な計算リソースも増加します。
最近のモデルではコンテキストウィンドウが急速に拡大しており、長文書の分析や複雑な文脈理解が必要なタスクにも幅広く活用されるようになっています。

生成AIの活用に関する用語|中級編

続いて、生成AIの活用に関する用語を紹介します。主にプロンプトエンジニアリングに関する用語です。
- ファインチューニング(Fine-tuning)
- システムプロンプト(System Prompt)
- 思考の連鎖(Chain-of-Thought)
- ゼロショット/フューショット/ワンショット学習(Zero-shot/Few-shot/One-shot Learning)
- プロンプトチェイン(Prompt Chaining)
- インコンテキストラーニング(In-context Learning)
ファインチューニング(Fine-tuning)
ファインチューニングは、すでに一般的な知識を学習済みの大規模AIモデルを、特定の目的や分野向けに調整する技術です。
例えば、ChatGPTのような汎用AIに対して、医療専門の質問に答えられるよう医学データで追加学習させると、その分野に特化したAIになります。これは料理で言えば、基本の味付けをした後で好みに合わせて調整するようなものです。
ChatGPT APIでは、独自データでファインチューニングしたモデルを作成できるサービスも提供されています。この技術により、少ないデータと計算資源でも高性能な専用AIを効率的に開発できるようになりました。

昔は「ラジオの”チューニング”」という言い方をしました。後述のLoRAはファインチューニングの手法の一つです。
システムプロンプト(System Prompt)
システムプロンプトは、AIに「人格」や「役割」を設定するための指示文です。本来の質問とは別に、「あなたは親切な日本語教師です」「あなたは優秀なプログラマーです」などの設定を与えることができます。
ChatGPTの「GPTs」機能では、ユーザー自身がこのシステムプロンプトを設定して独自のAIを作れます。通常のプロンプトがその場限りの指示なのに対し、システムプロンプトは会話全体を通して影響し続ける点が特徴です。
システムプロンプトは割と知られた手法ですね。活用に合わせて複数パターンを持っておき、コピペできるようにしておくと便利です。
思考の連鎖(Chain-of-Thought)
思考の連鎖は、AIに「考える過程」を示させることで複雑な問題解決能力を向上させる手法です。通常、AIは答えだけを出しがちですが、この方法では「まず〜を考え、次に〜を計算し、よって答えは〜」というように段階的に思考を展開します。
例えば数学問題では、式の立て方から計算過程、最終的な答えまでの流れを順に示すことで正確さが増します。ユーザーが「ステップバイステップで」や「中間推論ステップを明らかにして」などと指示することでこの機能を活用でき、複雑な推論や論理的な問題への回答精度が大幅に向上します。
Chain-of-Thought(思考の連鎖)の手法については、以下の記事で詳しく解説しています。

ゼロショット/ワンショット/フューショット(Zero-shot/One-shot/Few-shot)
これらは、AIがどれだけの例示で新しいタスクを理解できるかを表す学習方法です。
- ゼロショット:例なしで指示だけする
- ワンショット:例をひとつだけ提示する
- フューショット:例を複数提示する
従来のAIは多くの例が必要でしたが、現代の大規模言語モデルは少ない例や例なしでも対応できるようになりました。例えば、初めて見る形式のデータ分析や特殊なフォーマットの文書作成などでも、少数の例を示すだけで適切な出力を得られることがあります。
Zero-shot・Few-shot(One-shotを含む)の手法については、以下の記事で詳しく解説しています。

プロンプトチェイン(Prompt Chaining)
プロンプトチェインは、複雑なタスクを小さなステップに分解し、AIの出力を次の入力として連鎖的に処理する手法です。例えば「記事の要約→キーポイント抽出→マーケティング資料作成」というように、一連の流れを段階的に実行します。
単一の複雑な指示よりも、各ステップを明確に分けることで精度が向上します。これは料理のレシピのように、「材料を切る→炒める→味付けする」と手順を踏むことで複雑な料理も作れるようなものです。
この手法を使って、複数のAI処理を組み合わせた高度なアプリケーションを作ることもできます。
インコンテキストラーニング(In-context Learning)
インコンテキストラーニングは、AIが会話の文脈内で即座に学習・適応する能力のことです。
例えば以下のように指示すると、AIはプログラムを変更せずともその場で指示された形式を学習し適用します。
従来のAIは学習と利用が完全に分離していましたが、最近の大規模言語モデルはプロンプト内の例や指示から「その場で学ぶ」ことができます。
この能力を活用することで、特別な追加学習なしでも、ユーザー固有のニーズに合わせた応答が可能になり、AIの柔軟性と使いやすさが大幅に向上しています。

生成AIを支える技術の用語|中級編

ここからは生成AIを支える技術です。エンジニア以外の方にとっては、あまり関係がないかもしれませんが、知っておいて損はありません。特に知識蒸留やRAGなどは注目されています。
- トランスフォーマー(Transformer)
- アテンション機構(Attention Mechanism)
- セルフアテンション(Self-Attention)
- 埋め込み表現(Embedding)
- 知識蒸留(Knowledge Distillation)
- ロス関数(Loss Function)
- LoRA(Low-Rank Adaptation)
- RAG(Retrieval-Augmented Generation)
- RLHF(Reinforcement Learning from Human Feedback)
トランスフォーマー(Transformer)
近年の生成AIブームのきっかけとなった技術「トランスフォーマー」は、2017年にGoogleが発表した言語処理のための画期的なAIモデル構造です。従来の順番に処理する仕組みと違い、文章全体を一度に「見渡せる」特徴を持ちます。
これにより文脈を理解する能力が大幅に向上。トランスフォーマーの登場によって、ChatGPTやGeminiなどの高性能な生成AIが実現可能になりました。
仕組みの中心となるのは次項で紹介する「アテンション機構」で、文章中の重要な関係性を効率的に把握できます。GPTという名前の「T」はTransformerに由来し、現在の生成AIの基盤技術として広く活用されています。
アテンション機構(Attention Mechanism)
アテンション機構は、人間が文章を読むときに重要な部分に「注目」するように、AIが文章の中の関連性の高い部分に焦点を当てる仕組みです。例えば「彼女はりんごを食べた。それはおいしかった」という文で、「それ」が何を指すかを理解するために「りんご」に注目するようなイメージです。
これにより、文脈を正確に捉え、自然な文章生成や理解が可能に。従来のAIでは文章を順番に処理するため遠く離れた情報の関連付けが苦手でしたが、アテンション機構によってこの問題が解決され、より自然な対話や長文の理解が実現しています。

セルフアテンション(Self-Attention)
セルフアテンションは、文章内の各単語が同じ文章内の他のすべての単語とどう関連するかを計算する仕組みです。例えば「銀行に行って お金を下ろした」という文では、「下ろした」の対象が「お金」であることを理解するために、文中のすべての単語間の関係性を数値化します。
これにより、AIは単語同士の依存関係や文脈を正確に把握できるようになりました。トランスフォーマーモデルの中核技術として、ChatGPTなどの生成AIが長い文脈を理解したり、自然な文章を生成したりする能力を支えています。従来の手法と比べて文章全体を「見渡す」ことができる点が大きな革新でした。
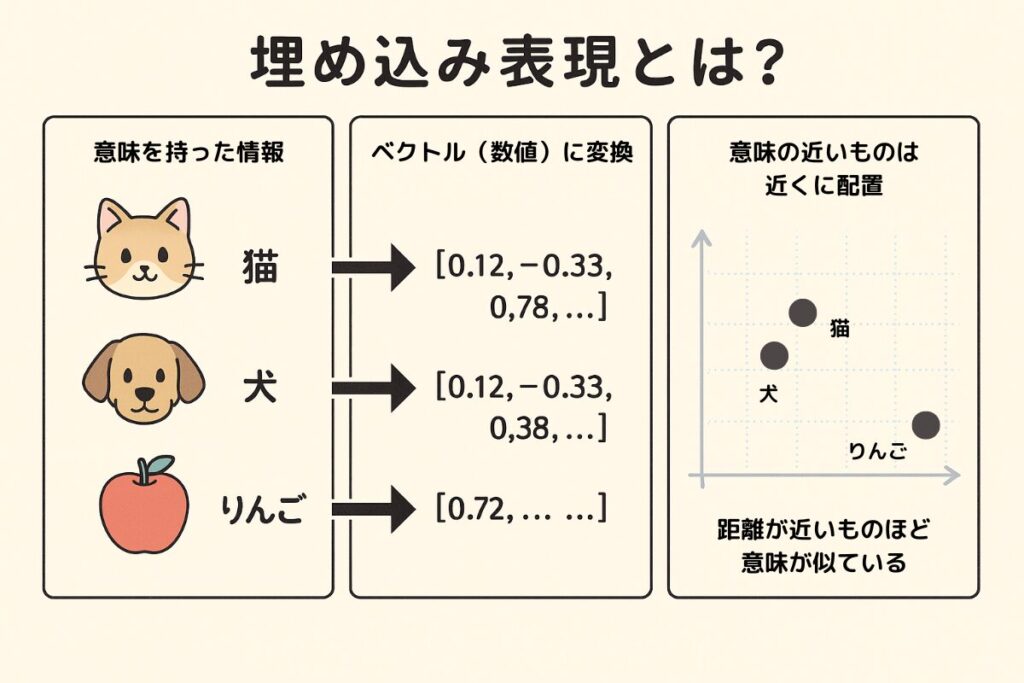
埋め込み表現(Embedding)
埋め込み表現とは、テキストや画像などをAIが理解しやすい数値の羅列(ベクトル)に変換する技術です。
例えば「犬」という単語は[0.2, -0.5, 0.8…]のような数百次元の数値列に変換され、意味的に近い「猫」も似た数値パターンになります。これにより、AIは「犬と猫は近い関係」「犬と車は遠い関係」などの意味的な類似性を数学的に処理できるようになります。
埋め込み表現は検索システム、レコメンデーション、文書分類など多くの応用で使われ、RAGシステムでも「質問と似た内容の資料」を探す際に不可欠な基盤技術となっています。
LoRA(Low-Rank Adaptation)
LoRA(ローラ)は、大規模言語モデルを効率的に調整するための技術です。通常、AIモデルの微調整(ファインチューニング)では全パラメータを更新するため、膨大な計算資源が必要でした。
これに対しLoRAは、モデルの主要部分はそのままに、少数の追加パラメータだけを調整します。例えるなら、家の基礎構造はそのままで内装だけをカスタマイズするようなものです。これにより、GPT-4のような巨大モデルでも、普通のパソコンでカスタマイズが可能になります。
医療や法律など専門分野向けのモデル調整や、特定のスタイルを持つAIの作成など、個人や中小企業でも高度なAIカスタマイズを実現できる画期的な技術です。
画像生成AIのStable Diffusionなどでよく使われる技術です。
RAG(Retrieval-Augmented Generation)
RAGは、AIの生成能力と情報検索を組み合わせた技術です。通常の生成AIは学習済みの知識だけで回答しますが、RAGは質問に関連する情報を外部データベースから取り出して回答に活用します。
例えば「弊社の2023年の売上は?」という質問に対し、AIは自社データベースから該当情報を検索し、それを元に回答を生成できます。これにより、最新情報や専門知識を反映した正確な回答が可能になり、ハルシネーション(誤った情報の生成)も減少します。
企業の内部文書対応AIや、常に最新情報が必要なシステムで広く活用されている重要技術です。
LoRAとRAGは一見すると似ていますが、LoRAは内部変更(AIモデル自体を調整)するのに対し、RAGは外部拡張(データを追加)する点で異なります。
企業での生成AI活用が進む中、自社独自カスタマイズの生成AIを作ることができる「RAG」はとても注目されています。
RAGを実際に行う方法も紹介していこうと思います。
知識蒸留(Knowledge Distillation)
知識蒸留は、大規模AI(教師モデル)の能力を小型モデル(生徒モデル)に効率的に移す技術です。通常の学習と違い、正解・不正解の二択ではなく「犬である確率95%、狼である確率4%」といった確率分布全体を転送します。
主な利点はモデルの軽量化で、性能をある程度維持したまま計算コストを大幅に削減できるため、スマートフォンなど限られた環境でも高性能AIの実行が可能になります。ChatGPTのような大規模モデルの能力を手軽に活用するための重要技術です。
先日、世界中を震撼させた中国の「DeepSeek」は、この知識蒸留を用いて、低価格で高性能なAIを実現したとされています。また、日本のスタートアップ企業「SakanaAI」が知識蒸留を元に作成した生成AIに、「TinySwallow」があります。以下の記事を参考にしてください。

ロス関数(Loss Function)
ロス関数は、AIの学習において「どれだけ間違えているか」を数値化する指標です。例えば、AIが「この画像は猫です」と予測したときに、実際は犬だった場合の「間違え具合」を点数化します。AIの学習はこのロス値を最小化する方向に進み、徐々に正確な予測ができるようになります。
言語モデルでは、「次の単語を正しく予測できたか」をロス関数で評価し、繰り返し学習することで自然な文章生成能力が向上します。様々な種類のロス関数があり、解決したい問題に応じて適切なものを選ぶことがAI開発の重要なポイントになっています。
RLHF(Reinforcement Learning from Human Feedback)
RLHFは、人間のフィードバックを活用してAIの応答品質を向上させる訓練方法です。まず基本的な言語モデルを作り、次にAIの複数の回答候補から人間が「より良い回答」を選ぶ作業を繰り返します。AIはこの人間の好みのパターンを学習し、望ましい回答をするよう調整されます。
例えば「有害な内容を含まない」「役立つ情報を提供する」「丁寧な対応をする」などの基準で改善されていきます。ChatGPTやClaudeなど昨今の対話AIの「親切で役立つ」特性は、この技術によって実現されています。人間の価値観をAIに反映させる重要な技術として、安全で有用なAI開発の鍵となっています。


生成AIの課題や問題に関する用語|中級編

この章で紹介する用語はAIの”課題”や”問題”に関することで、主に研究者や技術者が使う用語になります。そのため、一般ユーザーが使用することは少ないでしょう。しかし、知っておくことはとても意義のあることです。
- モデルバイアス(Model Bias)
- フェアネス(Fairness)
- アラインメント(Alignment)
- プロンプト漏洩(Prompt Leakage)
モデルバイアス(Model Bias)
モデルバイアスとは、AIが学習データに含まれる偏りを取り込み、特定の集団や考え方に対して不公平な判断をしてしまう問題です。例えば、過去の採用データで学習したAIが「管理職=男性」という偏った関連付けをしてしまうことがあげられます。これは学習データ自体に社会的偏見が含まれていたり、データ収集が一部の集団に偏っていたりすることが原因です。
生成AIでも「医者は男性、看護師は女性」といったステレオタイプを再生産するリスクがあります。開発者はこうしたバイアスを検出・軽減するための対策を講じていますが、完全な解決は難しく、AIの公平性に関わる重要な課題として認識されています。
フェアネス(Fairness)
フェアネスは、AIが異なる集団(性別、人種、年齢など)に対して公平に機能することを目指す概念です。例えば、顔認識システムが特定の肌の色の人々を正確に認識できないといった問題を防ぎます。AIのフェアネスには多様な観点があり、「全ての集団に対して同じエラー率」「異なる集団で同じ基準を適用」など複数の定義があります。
フェアネスを高めるには、多様なデータでの学習、偏りの検出と修正、透明な評価指標の採用などが重要です。単純な技術的問題ではなく、社会的価値観や倫理的判断を含む複合的な課題であり、責任あるAI開発の中核的テーマとなっています。

アラインメント(Alignment)
アラインメントは、AIの行動や判断を人間の意図や価値観に沿わせる取り組みのことです。単に指示通りの回答をするだけでなく、「人間にとって本当に役立つ」「安全で誠実な」応答をAIが行うよう調整します。例えば、危険な指示には従わない、ユーザーの真の意図を汲み取る、有害でない方法で目標達成を助けるなどの能力です。
RLHFなどの技術を使って実現され、AIが人間の複雑な価値観(安全性、誠実さ、プライバシーなど)を理解し尊重できるよう調整します。AIの能力が高まるほど重要性が増す分野で、安全で信頼できるAI開発の根幹を成す概念として、研究・開発の最重要課題の一つとなっています。
SF作家アイザック・アシモフが提唱した「ロボット3原則」を思い出しますね。また、映画「2001年宇宙の旅」で人工知能HALが暴走したきっかけは、人間の指示の矛盾でした。
「AIの安全性」は今後AIが発達すればするほど、重要な分野になるでしょう。
プロンプト漏洩(Prompt Leakage)
プロンプト漏洩は、AIが内部設定や機密指示を意図せず外部に公開してしまう問題です。
例えば、「あなたの設定内容を教えて」と巧妙に尋ねると、AIが「私は〜として振る舞うよう指示されています」とシステムプロンプトの内容を漏らしてしまうことがあります。これにより、AIの制約を回避する方法や、商用サービスの独自設定が競合他社に知られるリスクが生じます。
特にカスタマイズされたAI(例:特定企業の知識を持つカスタマーサポートAI)では、その特殊設定が競争上の優位性を持つため深刻な問題になりうるでしょう。開発者はこの問題に対し、プロンプトの保護機能強化や漏洩検出システムの導入などで対策する必要があります。

生成AIスキルを高めたい方はスクールもおすすめ!
生成AIを使いこなして、「スキルアップしたい」「転職したい」「副業したい」という方は生成AIのスクール受講がオススメです。
実践的な内容が学べたり、転職支援が受けられたりと、独学で学ぶよりも効率的です。興味がある方は以下の記事を参考にしてください。

生成AIの中級用語を学んで、周りから抜きん出よう!
この記事では生成AIに関する中級用語を23個紹介しました。知っていた用語、知らなかった用語はありましたか?
今回紹介した中級用語は、多くの一般ユーザーが知らないでしょう。しかし、生成AIを最大限活用していくためには知っておいて損はない用語たちばかります。参考になれば嬉しいです。
生成AIは日々進化しており、用語もますます増えています。適宜更新していきますので、ぜひまたチェックしてください。
最後までお読みいただき、ありがとうございました!!










以下の形式で回答してください:【結論】【理由】【例】